
 YAML、Pod、Job、CronJob、ConfigMap、Secret
YAML、Pod、Job、CronJob、ConfigMap、Secret
# 1. YAML:Kubernetes世界里的通用语
Kubernetes世界里的标准工作语言是 YAML。
# 1.1 声明式与命令式是怎么回事
YAML 是“声明式”。
Docker命令和Dockerfile就属于“命令式”,大多数编程语言也属于命令式,它的特点是交互性强,注重顺序和过程,你必须“告诉”计算机每步该做什么,所有的步骤都列清楚,这样程序才能够一步步走下去,最后完成任务,显得计算机有点“笨”。
“声明式”,在Kubernetes出现之前比较少见,它与“命令式”完全相反,不关心具体的过程,更注重结果。我们不需要“教”计算机该怎么做,只要告诉它一个目标状态,它自己就会想办法去完成任务,相比起来自动化、智能化程度更高。
以“打车”来形象地解释一下“命令式”和“声明式”的区别。
- 假设你要打车去高铁站,但司机不熟悉路况,你就只好不厌其烦地告诉他该走哪条路、在哪个路口转向、在哪里进出主路、停哪个站口。虽然最后到达了目的地,但这一路上也费了很多口舌,发出了无数的“命令”。很显然,这段路程就属于“命令式”。
- 同样是去高铁站,但司机经验丰富,他知道哪里有拥堵、哪条路的红绿灯多、哪段路有临时管控、哪里可以抄小道,此时你再多嘴无疑会干扰他的正常驾驶,所以,你只要给他一个“声明”:我要去高铁站,接下来就可以舒舒服服地躺在后座上休息,顺利到达目的地了
在这个“打车”的例子里,Kubernetes就是这样的一位熟练的司机,Master/Node架构让它对整个集群的状态了如指掌,内部的众多组件和插件也能够自动监控管理应用。我们最好是做一个“ 甩手掌柜”,用“声明式”把任务的目标告诉它,比如使用哪个镜像、什么时候运行,让它自己去处理执行过程中的细节。
那么,YAML 语言就是给 Kubernetes 发出一个“声明”的方式。
容器技术里的Shell脚本和Dockerfile可以很好地描述“命令式”,但对于“声明式”就不太合适了
# 1.2 什么是 YAML
YAML v.s. XML:
- XML 是一种类似 HTML 的标签式语言,有很多繁文缛节。
- YAML 实质上与XML完全不同,更适合人类阅读,计算机解析起来也很容易
把YAML的数组、对象组合起来,我们就可以描述出任意的Kubernetes资源对象。
# 1.3 什么是 API 对象
YAML语言只相当于“语法”,要与Kubernetes对话,我们还必须有足够的“词汇”来表示“语义”。作为一个集群操作系统,Kubernetes归纳总结了Google多年的经验,在理论层面抽象出了很多个概念,用来描述系统的管理运维工作,这些概念就叫做“ API对象”。
说到这个名字,你也许会联想到上次课里讲到的Kubernetes组件 apiserver。没错,它正是来源于此。因为apiserver是Kubernetes系统的唯一入口,外部用户和内部组件都必须和它通信,而它采用了HTTP协议的URL资源理念,API风格也用RESTful的GET/POST/DELETE等等,所以,这些概念很自然地就被称为是“API对象”了。
那都有哪些API对象呢?
使用 kubectl api-resources 来查看当前Kubernetes版本支持的所有对象:
kubectl api-resources
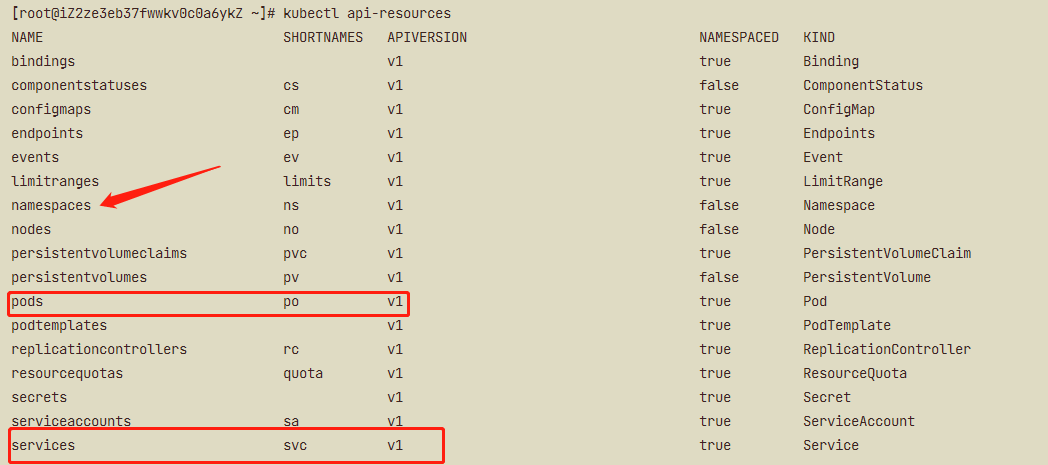
在输出的“NAME”一栏,就是对象的名字,比如ConfigMap、Pod、Service等等,第二栏“SHORTNAMES”则是这种资源的简写,在我们使用kubectl命令的时候很有用,可以少敲几次键盘,比如Pod可以简写成po,Service可以简写成svc。
在使用kubectl命令的时候,你还可以加上一个参数 --v=9,它会显示出详细的命令执行过程,清楚地看到发出的HTTP请求,比如:
kubectl get pod --v=9
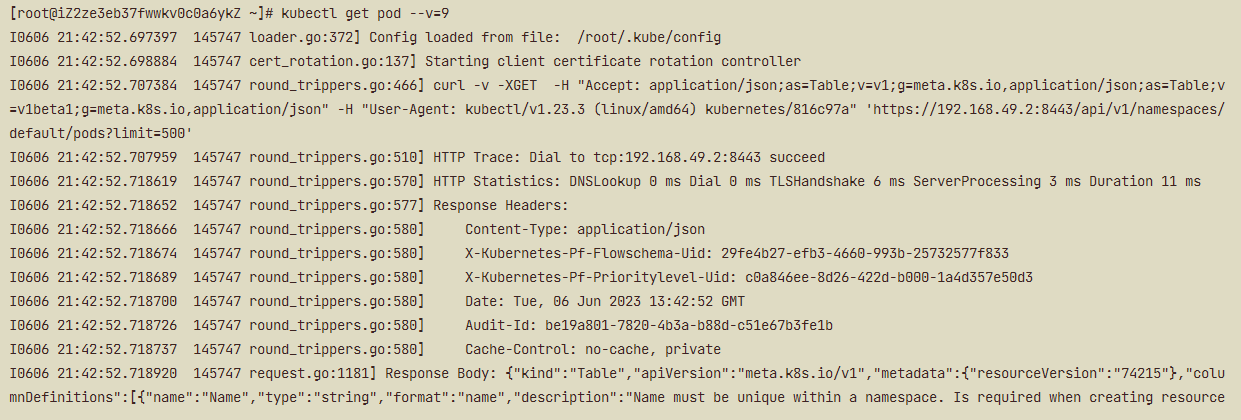
从截图里可以看到,kubectl客户端等价于调用了curl,向8443端口发送了HTTP GET 请求,URL是 /api/v1/namespaces/default/pods。
目前的Kubernetes 1.23版本有50多种API对象,全面地描述了集群的节点、应用、配置、服务、账号等等信息,apiserver会把它们都存储在数据库etcd里,然后kubelet、scheduler、controller-manager等组件通过apiserver来操作它们,就在API对象这个抽象层次实现了对整个集群的管理。
# 1.4 如何描述API对象
Kubernetes把集群里的一切资源都定义为API对象,通过RESTful接口来管理。描述API对象需要使用YAML语言,必须的字段是 apiVersion、kind、metadata。
之前我们使用 kubectl 运行 nginx 的命令用的是命令式的 kubectl run:
kubectl run ngx --image=nginx:alpine
下面看一下如何以 YAML 语言来声明式地在 k8s 中描述并创建 API 对象。在 YAML 中,我们需要说清楚我们的目标状态,让 Kubernetes 自己去决定如何拉取镜像并运行:
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod
labels:
env: demo
owner: nrich
spec:
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看出,这里是创建一个 pod,要使用 nginx:alpine 的 image 来创建一个 container,并开放 80 端口,而其他部分就是 k8s 对 API 对象强制的格式要求了。
因为API对象采用标准的 HTTP 协议,为了方便理解,我们可以借鉴一下 HTTP 的报文格式,把 API 对象的描述分成“header”和“body”两部分。
header 包含的是 API 对象的基本信息,有三个字段:
- apiVersion:表示操作这种资源的 API 版本号,由于 Kubernetes 的迭代速度很快,不同的版本创建的对象会有差异,为了区分这些版本就需要使用 apiVersion 这个字段,比如 v1、v1alpha1、v1beta1 等等。
- kind:表示资源对象的类型,比如 Pod、Node、Job、Service 等。
- metadata:表示的是资源的一些元信息,也就是用来标记对象,方便 Kubernetes 管理的一些信息。在上面的示例中有两个元信息:
- name:给 pod 起了个名字
- labels:给 pod 贴上一些便于查找的标签,分别是
env和owner。
以上信息都被 kubectl 用于生成 HTTP 请求发给 apiserver,你可以用 --v=9 参数在请求的 URL 里看到它们,比如:
https://192.168.49.2:8443/api/v1/namespaces/default/pods/ngx-pod
header 中的 apiVersion、kind、metadata 这三个字段都是任何对象都必须有的,而 body 部分则会与对象特定相关,每种对象会有不同的规格定义,在 YAML 里就表现为 spec 字段(即 specification),表示我们对对象的“期望状态”(desired status)。
还是来看这个 Pod,它的 spec 里就是一个 containers 数组,里面的每个元素又是一个对象,指定了名字、镜像、端口等信息:
spec:
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
2
3
4
5
6
现在把这些字段综合起来,我们就能够看出,这份 YAML 文档完整地描述了一个类型是 Pod 的 API 对象,要求使用 v1 版本的 API 接口去管理,其他更具体的名称、标签、状态等细节都记录在了 metadata 和 spec 字段等里。
使用 kubectl apply、 kubectl delete,再加上参数 -f,你就可以使用这个 YAML 文件,创建或者删除对象了:
kubectl apply -f ngx-pod.yml # 创建 API 对象
kubectl delete -f ngx-pod.yml # 删除 API 对象
2
Kubernetes 收到这份“声明式”的数据,再根据 HTTP 请求里的 POST/DELETE 等方法,就会自动操作这个资源对象,至于对象在哪个节点上、怎么创建、怎么删除完全不用我们操心。
# 1.5 如何编写 YAML
这么多字段,我们怎样才能编写正确的 YAML 呢?
这个问题的最权威的答案自然是 k8s 的官方文档 (opens new window),API 对象的所有字段都可以在里面找到。但这内容太多,下面介绍一些实用的小技巧。
第一个技巧其实前面已经说过了,就是 kubectl api-resources 命令,它会显示出资源对象相应的API版本和类型,比如Pod的版本是“v1”,Ingress的版本是“networking.k8s.io/v1”,照着它写绝对不会错。
第二个技巧,是命令 kubectl explain,它相当于是Kubernetes自带的API文档,会给出对象字段的详细说明,这样我们就不必去网上查找了。比如想要看Pod里的字段该怎么写,就可以这样:
kubectl explain pod
kubectl explain pod.metadata
kubectl explain pod.spec
kubectl explain pod.spec.containers
2
3
4
使用前两个技巧编写 YAML 就基本上没有难度了。
⭐️ 第三个技巧就是kubectl的两个特殊参数 --dry-run=client 和 -o yaml,前者是空运行,后者是生成YAML格式,结合起来使用就会让 kubectl 不会有实际的创建动作,而只生成 YAML 文件。例如,想要生成一个Pod的YAML样板示例,可以在 kubectl run 后面加上这两个参数:
kubectl run ngx --image=nginx:alpine --dry-run=client -o yaml
就会生成一个绝对正确的 YAML 文件:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ngx
name: ngx
spec:
containers:
- image: nginx:alpine
name: ngx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
接下来你要做的,就是查阅对象的说明文档,添加或者删除字段来定制这个 YAML 了。
这个小技巧还可以再进化一下,把这段参数定义成Shell变量(名字任意,比如$do/$go,这里用的是 $out),用起来会更省事,比如:
export out="--dry-run=client -o yaml"
kubectl run ngx --image=nginx:alpine $out
2
今后除了一些特殊情况,我们都不会再使用 kubectl run 这样的命令去直接创建 Pod,而是会编写 YAML,用“声明式”来描述对象,再用 kubectl apply 去发布 YAML 来创建对象。
# 1.6 课外小贴士
- .推荐一个知名的 JSON/YAML 工具网站: BEJSON (opens new window),支持 JSON 格式校验也可以转换 YAML。
- Kubernetes 的 API 版本命名有明确规范,正式版本(GA,Generally available) 是 v1 这样的纯数字,试验性质、不稳定的是 alpha,比较稳定、即将发布的是 beta。
- 因为 Kubernetes 的开发语言是 Go,所以 API 对象字段用的都是 Go 语法规范,例如字段命名遵循“Camel Case”,类型是 boolean、string、[]Object 等。
# 2. Pod:如何理解这个Kubernetes里最核心的概念?
# 2.1 为什么要有 Pod
Pod这个词原意是“豌豆荚”,后来又延伸出“舱室”“太空舱”等含义,形象地来说Pod就是包含了很多组件、成员的一种结构。
为了解决多应用联合运行的问题,同时还要不破坏容器的隔离,就需要在容器外面再建立一个“收纳舱”,让多个容器既保持相对独立,又能够小范围共享网络、存储等资源,而且永远是“绑在一起”的状态。
所以,出现了Pod的概念,容器正是“豆荚”里那些小小的“豌豆”,你可以在Pod的YAML里看到,“spec.containers”字段其实是一个数组,里面允许定义多个容器。Pod 能让进程住得更舒服。
TODO: 待补充
# 3. Job/CronJob:为什么不直接用Pod来处理业务?
Kubernetes的核心对象Pod,用来编排一个或多个容器,让这些容器共享网络、存储等资源,总是共同调度,从而紧密协同工作。Pod比容器更能够表示实际的应用,所以Kubernetes不会在容器层面来编排业务,而是把Pod作为在集群里调度运维的最小单位。
前面我们也看到了一张Kubernetes的资源对象关系图,以Pod为中心,延伸出了很多表示各种业务的其他资源对象。那么你会不会有这样的疑问:Pod的功能已经足够完善了,为什么还要定义这些额外的对象呢?为什么不直接在Pod里添加功能,来处理业务需求呢?
这个问题体现了Google对大规模计算集群管理的深度思考,今天我就说说Kubernetes基于Pod的设计理念,先从最简单的两种对象——Job和CronJob讲起。
# 3.1 为什么不直接使用Pod
# 小结
好了,今天我们以面向对象思想分析了一下Kubernetes里的资源对象设计,它强调“职责单一”和“对象组合”,简单来说就是“对象套对象”。
通过这种嵌套方式,Kubernetes里的这些API对象就形成了一个“控制链”:
CronJob使用定时规则控制Job,Job使用并发数量控制Pod,Pod再定义参数控制容器,容器再隔离控制进程,进程最终实现业务功能,层层递进的形式有点像设计模式里的Decorator(装饰模式),链条里的每个环节都各司其职,在Kubernetes的统一指挥下完成任务。
小结一下今天的内容:
- Pod是Kubernetes的最小调度单元,但为了保持它的独立性,不应该向它添加多余的功能。
- Kubernetes为离线业务提供了Job和CronJob两种API对象,分别处理“临时任务”和“定时任务”。
- Job的关键字段是
spec.template,里面定义了用来运行业务的Pod模板,其他的重要字段有completions、parallelism等 - CronJob的关键字段是
spec.jobTemplate和spec.schedule,分别定义了Job模板和定时运行的规则。
# 4. ConfigMap/Secret:怎样配置、定制我的应用
本节要解决的问题:使用 YAML 语言来定义 API 对象,再组合起来实现动态配置。
下面讲解Kubernetes里专门用来管理配置信息的两种对象: ConfigMap 和 Secret,使用它们来灵活地配置、定制我们的应用。
# 4.1 ConfigMap/Secret
首先你要知道,应用程序有很多类别的配置信息,但从数据安全的角度来看可以分成两类:
- 一类是明文配置,也就是不保密,可以任意查询修改,比如服务端口、运行参数、文件路径等等。
- 另一类则是机密配置,由于涉及敏感信息需要保密,不能随便查看,比如密码、密钥、证书等等。
这两类配置信息本质上都是字符串,只是由于安全性的原因,在存放和使用方面有些差异,所以Kubernetes也就定义了两个API对象, ConfigMap 用来保存明文配置, Secret 用来保存秘密配置。
# 4.1.1 什么是ConfigMap
ConfigMap 的简写:“cm”,后面都可以直接用简写代替。用命令 kubectl create 来创建一个它的YAML样板。
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create cm info [--from-literal=k=v] $out
2
参数 --from-literal=k=v 是表示要生成带有“data”字段的YAML样板。注意,因为在ConfigMap里的数据都是Key-Value结构,所以 --from-literal 参数需要使用 k=v 的形式。
得到的样板文件大概是这个样子:
apiVersion: v1
kind: ConfigMap
metadata:
name: info
data:
k: v
2
3
4
5
6
把YAML样板文件修改一下,再多增添一些Key-Value,就得到了一个比较完整的ConfigMap对象:
apiVersion: v1
kind: ConfigMap
metadata:
name: info
data:
count: '10'
debug: 'on'
path: '/etc/systemd'
greeting: |
say hello to kubernetes.
2
3
4
5
6
7
8
9
10
11
现在就可以使用 kubectl apply 把这个YAML交给Kubernetes,让它创建ConfigMap对象了:
kubectl apply -f cm.yml
创建成功后,我们还是可以用 kubectl get、 kubectl describe 来查看ConfigMap的状态:
kubectl get cm
kubectl describe cm info
2
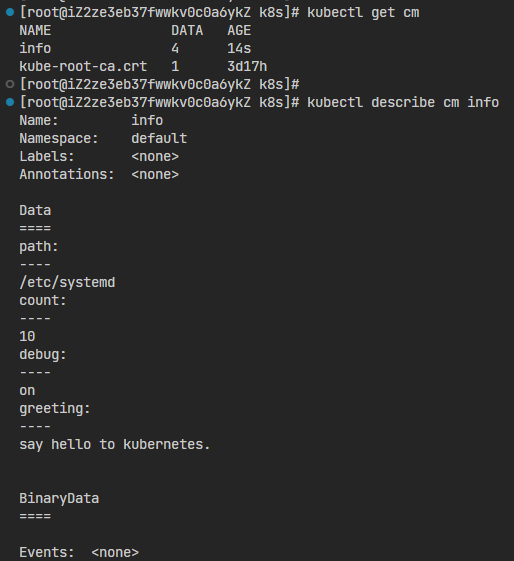
你可以看到,现在ConfigMap的Key-Value信息就已经存入了etcd数据库,后续就可以被其他API对象使用。
# 4.1.2 什么是Secret
Secret 和ConfigMap的结构和用法很类似,不过在Kubernetes里Secret对象又细分出很多类,比如:
- 访问私有镜像仓库的认证信息
- 身份识别的凭证信息
- HTTPS通信的证书和私钥
- 一般的机密信息(格式由用户自行解释)
前几种我们现在暂时用不到,所以就只使用最后一种,创建YAML样板的命令是 kubectl create secret generic ,同样,也要使用参数 --from-literal 给出Key-Value值:
kubectl create secret generic user --from-literal=name=root $out
得到的Secret对象大概是这个样子:
apiVersion: v1
kind: Secret
metadata:
name: user
data:
name: cm9vdA==
2
3
4
5
6
7
8
Secret对象只是“kind”字段由“ConfigMap”变成了“Secret”,后面同样也是“data”字段,里面也是Key-Value的数据。但Secret 不能像ConfigMap那样直接保存明文了,对数据使用了 BASE64 编码(根本算不上真正的加密)。所以 Secret 对象不让用户直接看到原始数据,起到一定的保密作用。
自己用Linux工具对数据进行 base64 编码
我们完全可以绕开kubectl,自己用Linux小工具“base64”来对数据编码,然后写入YAML文件,比如:
echo -n "123456" | base64
MTIzNDU2
2
要注意这条命令里的 echo ,必须要加参数 -n 去掉字符串里隐含的换行符,否则Base64编码出来的字符串就是错误的。
我们再来重新编辑Secret的YAML,为它添加两个新的数据,方式可以是参数 --from-literal 自动编码,也可以是自己手动编码:
apiVersion: v1
kind: Secret
metadata:
name: user
data:
name: cm9vdA== # root
pwd: MTIzNDU2 # 123456
db: bXlzcWw= # mysql
2
3
4
5
6
7
8
9
10
接下来的创建和查看对象操作和ConfigMap是一样的,使用 kubectl apply、 kubectl get、 kubectl describe:
kubectl apply -f secret.yml
kubectl get secret
kubectl describe secret user
2
3
4
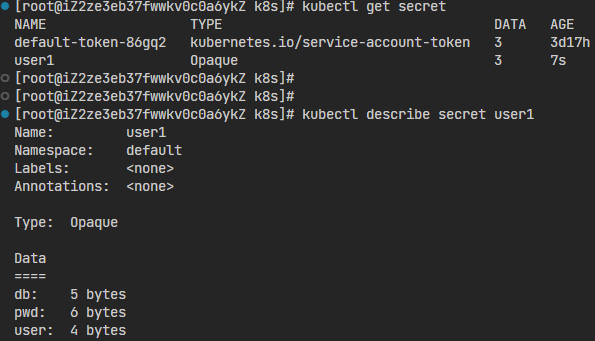
这样一个存储敏感信息的Secret对象也就创建好了,而且因为它是保密的,使用 kubectl describe 不能直接看到内容,只能看到数据的大小,你可以和ConfigMap对比一下。
# 4.2 如何使用
# 4.2.1 以环境变量的方式使用
下面我就把引用了ConfigMap和Secret对象的Pod列出来,给你做个示范,为了提醒你注意,我把“ env”字段提到了前面:
apiVersion: v1
kind: Pod
metadata:
name: env-pod
spec:
containers:
- env:
- name: COUNT
valueFrom:
configMapKeyRef:
name: info
key: count
- name: GREETING
valueFrom:
configMapKeyRef:
name: info
key: greeting
- name: USERNAME
valueFrom:
secretKeyRef:
name: user
key: name
- name: PASSWORD
valueFrom:
secretKeyRef:
name: user
key: pwd
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
这个Pod的名字是“env-pod”,镜像是“busybox”,执行命令sleep睡眠300秒,我们可以在这段时间里使用命令 kubectl exec 进入Pod观察环境变量。
你需要重点关注的是它的“env”字段,里面定义了4个环境变量, COUNT、 GREETING、 USERNAME、 PASSWORD。
对于明文配置数据, COUNT、 GREETING 引用的是ConfigMap对象,所以使用字段“ configMapKeyRef”,里面的“name”是ConfigMap对象的名字,也就是之前我们创建的“info”,而“key”字段分别是“info”对象里的 count 和 greeting。
同样的对于机密配置数据, USERNAME、 PASSWORD 引用的是Secret对象,要使用字段“ secretKeyRef”,再用“name”指定Secret对象的名字 user,用“key”字段应用它里面的 name 和 pwd 。
ConfigMap和Secret在Pod里的组合关系如图所示:
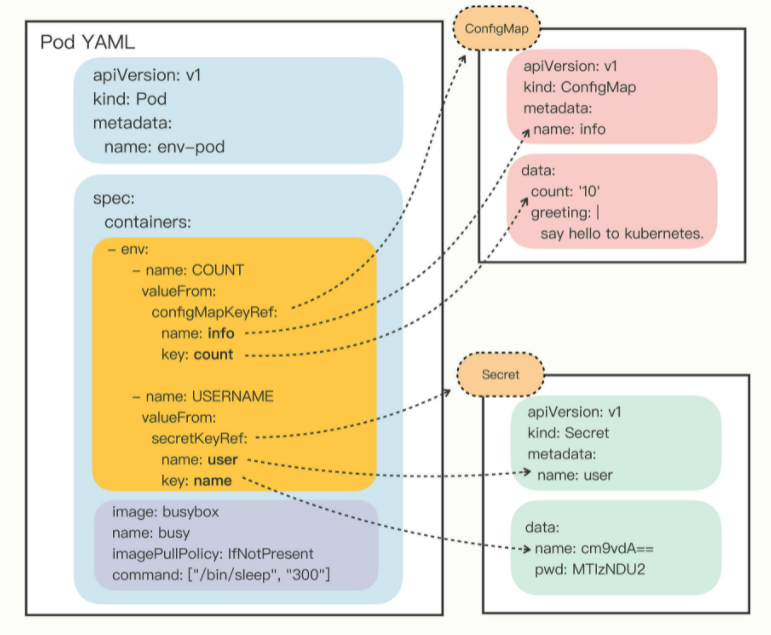
从这张图你就应该能够比较清楚地看出Pod与ConfigMap、Secret的“松耦合”关系,它们不是直接嵌套包含,而是使用“KeyRef”字段间接引用对象,这样,同一段配置信息就可以在不同的对象之间共享。
弄清楚了环境变量的注入方式之后,让我们用 kubectl apply 创建Pod,再用 kubectl exec 进入Pod,验证环境变量是否生效:
kubectl apply -f env-pod.yml
kubectl exec -it env-pod -- sh
echo $COUNT
echo $GREETING
echo $USERNAME $PASSWORD
2
3
4
5
6
7
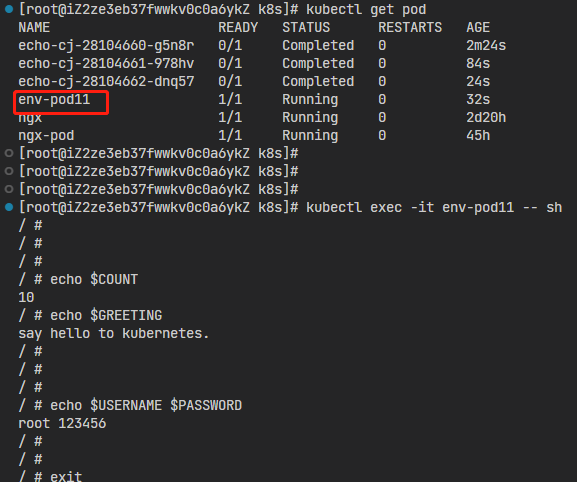
这张截图就显示了Pod的运行结果,可以看到在Pod里使用 echo 命令确实输出了我们在两个YAML里定义的配置信息,也就证明Pod对象成功组合了ConfigMap和Secret对象。
以环境变量的方式使用ConfigMap/Secret还是比较简单的,下面来看第二种加载文件的方式。
# 4.2.2 以Volume的方式使用
Kubernetes为Pod定义了一个“ Volume”的概念,可以翻译成是“存储卷”。如果把Pod理解成是一个虚拟机,那么Volume就相当于是虚拟机里的磁盘。
我们可以为Pod“挂载(mount)”多个Volume,里面存放供Pod访问的数据,这种方式有点类似 docker run -v,虽然用法复杂了一些,但功能也相应强大一些。
在Pod里挂载Volume很容易,只需要在“ spec”里增加一个“ volumes”字段,然后再定义卷的名字和引用的ConfigMap/Secret就可以了。要注意的是Volume属于Pod,不属于容器,所以它和字段“containers”是同级的,都属于“spec”。
下面我们先定义两个Volume,分别引用ConfigMap和Secret,名字是 cm-vol 和 sec-vol。有了Volume的定义之后,就可以在容器里挂载了,这要用到“ volumeMounts”字段,正如它的字面含义,可以把定义好的Volume挂载到容器里的某个路径下,所以需要在里面用“ mountPath”“ name”明确地指定挂载路径和Volume的名字。
把“ volumes”和“ volumeMounts”字段都写好之后,配置信息就可以加载成文件了。下图表示他们之间的引用关系:
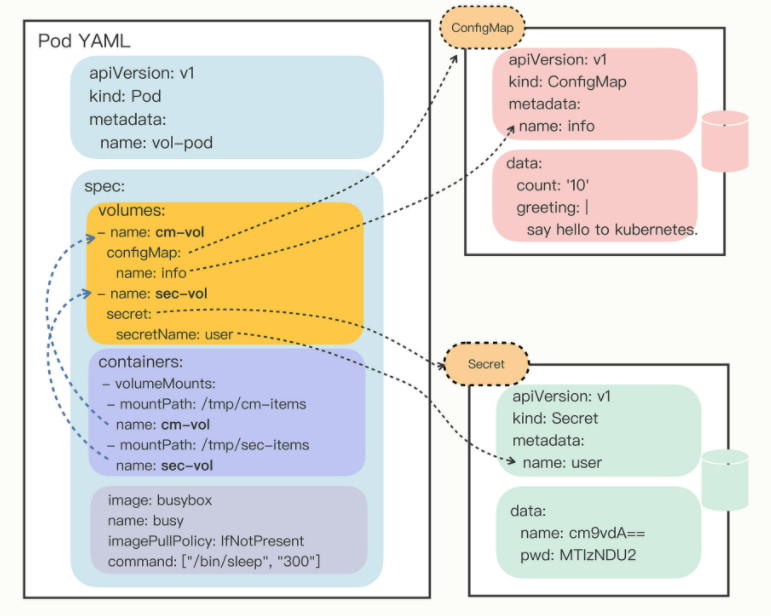
你可以看到,挂载Volume的方式和环境变量又不太相同。环境变量是直接引用了ConfigMap/Secret,而Volume又多加了一个环节,需要先用Volume引用ConfigMap/Secret,然后在容器里挂载Volume,有点“兜圈子”“弯弯绕”。
这种方式的好处在于:以Volume的概念统一抽象了所有的存储,不仅现在支持ConfigMap/Secret,以后还能够支持临时卷、持久卷、动态卷、快照卷等许多形式的存储,扩展性非常好。
现在我把Pod的完整YAML描述列出来,然后使用 kubectl apply 创建它:
apiVersion: v1
kind: Pod
metadata:
name: vol-pod11
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user1
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
image: busybox:latest
name: busy11
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
创建之后,我们还是用 kubectl exec 进入Pod,看看配置信息被加载成了什么形式:
kubectl apply -f vol-pod.yml
kubectl get pod
kubectl exec -it vol-pod -- sh
2
3
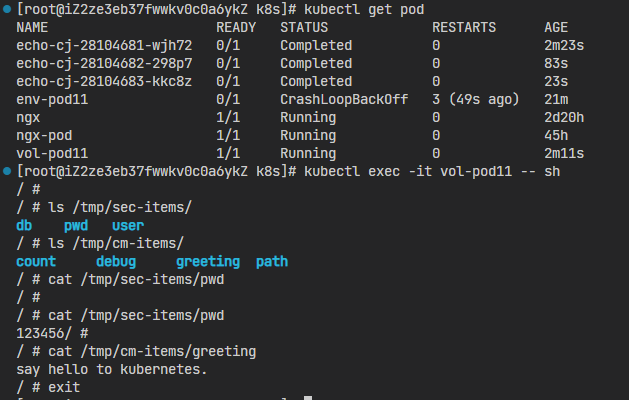
你会看到,ConfigMap和Secret都变成了目录的形式,而它们里面的Key-Value变成了一个个的文件,而文件名就是Key。(Key => 文件名,Value => 文件内容)
因为这种形式上的差异,以Volume的方式来使用ConfigMap/Secret,就和环境变量不太一样。环境变量用法简单,更适合存放简短的字符串,而Volume更适合存放大数据量的配置文件,在Pod里加载成文件后让应用直接读取使用。
# 4.3 小结
以上学习了两种在Kubernetes里管理配置信息的API对象ConfigMap和Secret,它们分别代表了明文信息和机密敏感信息,存储在etcd里,在需要的时候可以注入Pod供Pod使用。