
 Spring依赖注入原理
Spring依赖注入原理
# 1. 基本概念
依赖注入(Dependency Injection, DI):在系统运行时基于某个对象的使用需求,动态提供他所依赖的其他对象,通过依赖注入实现。
# 2. Spring依赖注入原理分析
Spring 中涉及大量类和组件之间的协作与交互。原理上讲,任何一个框架都存在一条核心执行流程,只要抓住这条主流程,我们就能把握框架的整体代码结构,Spring 也不例外。无论采用何种依赖注入机制,前提都是 SpringIoC 容器正常启动。因此,IoC 容器初始化就是我们理解和把握依赖注人实现机制的前提。
下面我们讲解 IoC 容器的初始化过程。结合 Bean 的生命周期,将其梳理为两大步骤:
- Bean 的注册
- Bean 的实例化
# 2.1 Bean 的注册
在使用Spring时,我们可以通过获取一个应用上下文(ApplicationContext)对象来操作各种 Bean,示例代码如下:
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
- 这里的 ApplicationContext 接口代表的就是一个Spring IoC 容器,而在 Spring 中存在大批 ApplicationContext 接口的实现类。如果使用基于注解的配置方式,就可以使用上述代码中的 AnnotationConfigApplicationContext 来初始化容器上下文对象。
看一下 AnnotationConfigApplicationContext 的启动流程,这一流程位于它的构造函数中,如下:
public AnnotationConfigApplicationContext(Class<?>...annotatedClasses) {
this();
//根据注解配置类注册 Bean
register(annotatedClasses);
//刷新容器
refresh();
}
public AnnotationConfigApplicationContext(String...basePackages) {
this();
//根据包路径配置扫描 Bean
scan(basePackages);
// 刷新容器
refresh();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 这两个构造函数的作用很明确,一个是根据注解配置类注册 Bean,另一个则是根据包路径配置扫描 Bean。
这里我们以 register() 方法为例,来讨论 Bean 的注册过程。该 register() 会依赖 AnnolatedBeanDeinitionReader 工具类来完成 Bean 的注册。这个工具类会遍历所有传入的 annotatedClasses 注解类,然后通过 doRegisterBean() 方法完成注册。
在 doRegisterBean() 方法中,包含了 Bean 注册过程中的三个核心步骤,如下图:
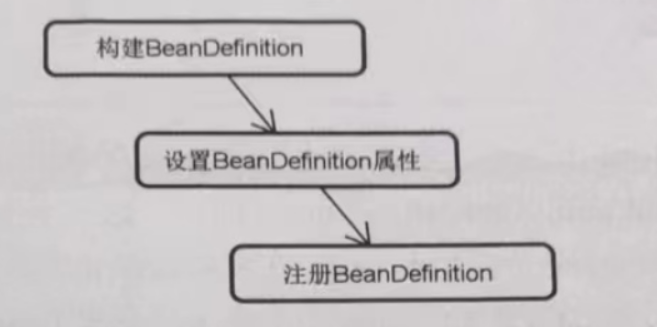
- 首先,我们构建用来描述 Bean 实例信息的 BeanDefinition 对象,这需要将注解配置类信息转成 AnnotatedGenericBeanDefinition 数据结构,而它就是一种 BeanDefinition,包含了 Bean 的构造函数参数、各种属性值以及所添加的注解信息。
- Bean 的属性值:如 Student 类的 age、name 等,就是属性
- 然后,我们设置 BeanDefinition 属性,这一步骤完成了对 @Scope、@Primary、@Lazy 等注解的处理。
- 最后,通过 registerBeanDefinition() 方法完成 Bean 的注册,该方法内部通过 ListableBeanFactory 的实现类 DefaultListableBeanFactory将 Bean 定义信息注册到 Spring IoC 容器中。
- ListableBeanFactory 是 Spring 中常用的一个 BeanFactory,通过这个接口,我们可以一次获取多个 Bean。
# 2.2 Bean 的实例化
上一小小节中的 Bean 的注册并未完成实例化,只是将 Bean 的定义加载到了容器中。
要根据注册的 Bean 的定义调用 ApplicationContext 接口的抽象实现类 AbstractApplicationContext 中的 refresh() 方法刷新容器,正如我们在前面看到的 AnnotationConfigApplicationContext 构造函数所执行的那样。可以说,refresh() 方法是整个 Spring 容器中最为核心的一个方法,我们这里只对 refresh() 中和依赖注入相关的部分讨论。
refresh() 方法中,
- obtainFreshBeanFactory() 方法完成 BeanDefinition 的注册并返回一个BeanFactory。对于 AnnotationConfigApplicationContext 而言,这一步实际上就是将 BeanDefinition 注册到 DefaultListableBeanFactory 而已,我们在前面已经介绍了这一步骤。
- 而 finishBeanFactorylnitialization() 方法才是真正的完成 Bean 实例化的入口。
在 finishBeanFactorylnitialization() 对 Bean 的实例化又经历了一番折腾:
- 完成 Bean 的实例化的代码实际上位于法它的子类 DefaultListableBeanFactory 中,的prelnstantiateSingletons() 方法;
- 该方法调用 getBean() 方法,可以从 BeanFactory 中获取 Bean,而 Bean 的初始化过程也被封装在这个方法中。
- 在 getBean() 中,发现实际上是由实现抽象方法 createBean() 的唯一 BeanFactory —— AbstractAutowireCapableBeanFactory 中,的 doCreateBean() 方法中真正完成 Bean 的创建。
doCreateBean() 方法中包含三个核心子方法,他们的名称和作用如下图,经过大量裁剪之后得到的代码如下所示。
protected object docreateBean(final String beanName, final RootBeanDefinitioimbd, final @Nullable object[] args) throws BeanCreationException {
//1. 初始化Bean
instanceWrapper =createBeanInstance(beanName,mbd,args);
//2. 初始化Bean实例
populateBean(beanName, mbd,instanceWrapper);
//3. 执行初始化 Bean 实例的回调
exposedObject=initializeBean(beanName,exposedObject,mbd);
return exposedObject;
}
2
3
4
5
6
7
8
9
10
11
12
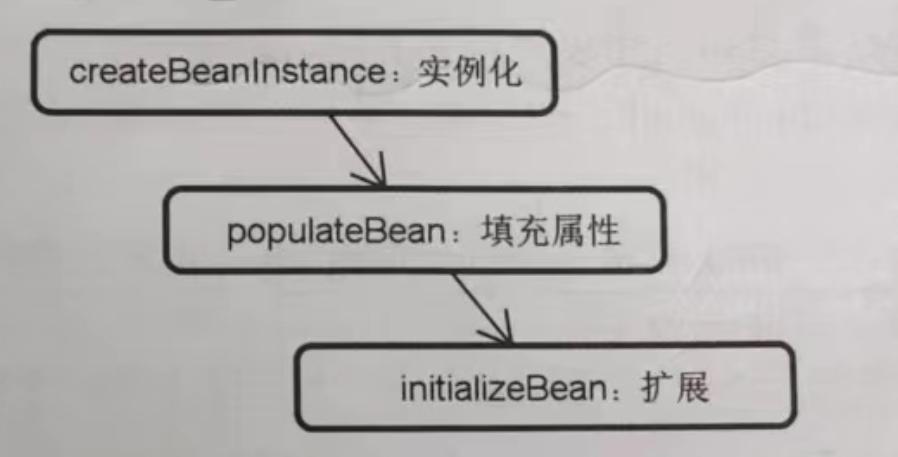
- createBeanInstance0 方法用于根据配置生成具体的 Bean,最终通过基于构造器的反射方法实现这一目标。请注意,执行完这一步之后,Bean 已经被创建了但还不完整,因为属性还没有被注入。
- 接下来的 populateBean() 方法就是用于实现属性的自动注人,包含 byName、byType 类型的自动装配,以及基于 @Autowired、@Value 注解的属性设值。执行完这一步之后,可以说 Bean 已经是完整的了。
- 最后的 initializeBean()方法则更多是一种扩展性的实现机制,用于在 Bean初始化完成之后执行一些定制化操作。
至此,针对整个 Bean 的注人过程(即 Bean 的注册和实例化),我们围绕核心流程做了剖析和总结。
# 3. Spring 循环依赖分析
使用 Ioc 容器时的一个常见问题:循环依赖。
在单例作用域下,Setter 方法注入能够解决循环依赖问题而构造器注入则不能。
对于单例作用域来说,Spring 容器在整个生命周期内,有且只有一个 Bean 对象,所以很容易想到这个对象应该存在于缓存中。Spring为了解决单例 Bean 的循环依赖问题,使用了三级缓存。这是 Spring 在设计和实现上的一大特色,也是开发人员在面试过程中经常遇到的话题。
# 3.1 三级缓存结构
所谓的三级缓存,在Spring中表现为三个 Map 对象,如下的代码所示:

这三个Map 对象定义在 DefaultSingletonBeanRegistry 类中,该类是 DefaultListableBeanFactory 的父类。
- singletonObjects 变量就是策一级缓存,用来持有完整的 Bean实例
- earlySingletonObjects 中存放的是那些提前暴露的对象,也就是已经创建但还没有完成属性汪人的对象,属于第二级缓存
- singletonFactories 存放用来创建earlySingletonObjects 的工厂对象,属于第三级缓存
# 3.2 三级缓存如何发挥作用的?
我们通过分析获取 Bean 的代码流程来理解对三级缓存的访问过程。
protected object getSingleton(String beanName, boolean allowEarlyReference) {
//首先从一级缓存singletonObjects 中获取Object
singletonObject = this.singletonObjects.get(beanName);
//如果获取不到,就从二级缓存 earlysingletonobjects 中获取
if (singletonobject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
//如果还是获取不到,就从三级缓存 singletonPactory 中获取
if (singletonObject == null && allowEarlyReference){
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null){
singletonObject = singletonFactory.getobject();
//一旦获取成功,就把对象从第三级缓存移动到第二级缓存中
this.earlySingletonobjects.put(beanName,singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
看了这段代码,可能还是不理解 Spring 为什么要这样设计。事实上,解决循环依赖的关键还是要围绕 Bean 的生命周期。Spring 解决循环依赖的诀窍就在于 singletonFactories 这个第三级缓存。
上一小小节我们介绍 Bean 的实例化时,我们知道它包含三个核心步骤,而在第一步和第二步之间,存在一个addSingletonFactory() 方法,用于初始化第三级缓存中的数据,他针对循环依赖问题暴露单例工厂类,代码如下图所示:
addSingletonFactory() 方法的具体代码就不在这里展开了。
addSingletonFactory() 方法的代码的执行时机是在已经通过构造函数创建 Bean,但还没有完成对 Bean 中完教属性的注人的时候。换句话说,Ben 已经可以被暴露出来进行识别了,但还不能正常使用。
# 3.3 循环依赖解决方案
接下来我们就来分析一下为什么通过这种机制就能解决循环依赖问题。
让我们回顾基于 Setter 方法注入的循环依赖场景:

现在我们就能够基于 Setter 方法注入来解决掉循环依赖了,整个流程如下图:
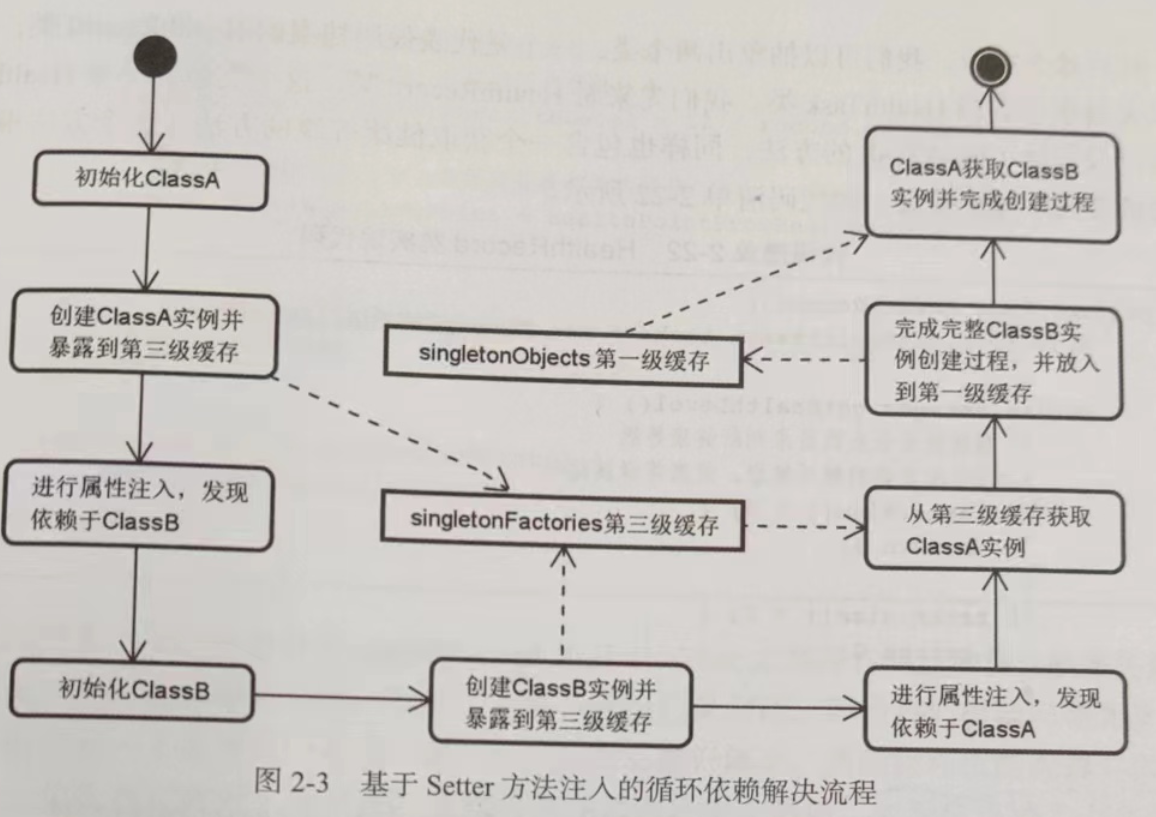
基于 Setter 方法注入解决循环依赖的具体描述(对上图的解释)
现在假设我们先初始化 ClassA。ClassA 首先通过 createBeanInstance() 方法创建了实例,并且将这个实例提前暴露到第三级缓存 singletonFactories 中。然后,ClassA 尝试通过 populateBean() 方法注人属性,发现自己依赖ClassB 这个属性,就会尝试去获取 ClassB的实例。
显然,这时候 ClassB 还没有被创建,所以要走创建流程。ClassB 在初始化第一步的时候发现自己依赖了 ClassA,就会尝试从第一级缓存 singletonObjects 去获取 ClassA实例。因为 ClassA 这时候还没有被创建完毕,所以它在第一级缓存和第二级缓存中都不存在。当尝试访问第三级缓存时,因为 ClassA 已经提前暴露了,所以 ClassB 能够通过singletonFactories拿到 ClassA 对象并顺利完成所有初始化流程。
ClassB 对象创建完成之后会被放到第一级缓存中,这时候 ClassA 就能从第一级缓存中获取 ClassB 的实例,进而完成 ClassA 的所有初始化流。这样 ClassA 和 ClassB 都能够功完成创建过程,
讲到这里,相信你也理解了为什么构造器注入无法解决循环依赖问题。这是因为构造器注人过程是发生在 Bean 初始化的第一个步骤 createBeanInstance() 中,而这个步骤还没有调用 addSingletonFactory0方法完成第三级缓存的构建,自然也就无法从该缓存中获取目标对象。